All of the discussion about ‘the best scientist’ has been in pursuit of one goal: to figure out the best [1] way to fund scientists.
As I stressed in the first and second part of this mini-series, it’s important to decide, beforehand, what exactly we want before calling something ‘the best.’ But, for sake of this post, let’s just accept that we have established those criteria.
 In order to understand the pitfalls that still remain, even after all of our hard work to decide on ‘bestness’, let’s imagine that we have six scientists who are wearing different color dresses.
In order to understand the pitfalls that still remain, even after all of our hard work to decide on ‘bestness’, let’s imagine that we have six scientists who are wearing different color dresses.
Our first task is to decide on what sort of funding scheme we want to use. Do we give the six scientists equal amounts of money? Or maybe we could distribute the money randomly? Based on their birthday or by throwing their applications down a flight of stairs with the lucky ones being those that go furthest.
I think you’ll agree with me that these options seem suboptimal. No, clearly, we want to rank the scientists somehow, ideally giving the most money to ‘the best’.
But measuring ‘bestness’ is hard and very time-consuming, and so we have to come up with a good proxy for this. After looking through a lot of data of scientific performance, we notice that scientists who wore purple tended to do ‘the best’, with blue being ‘second best’, etc.[2] And so that’s our straightforward funding scheme: rank the scientists by dress color.[3]
Sorted. Right?
Well, not quite. And there are (at least) three reasons why this scheme will break down for us.
1. Incomplete knowledge
Alas, dress color isn’t some sort of absolute, final trait. People (unlike the power rangers) change the color of their attire all the time. What our scientists wore yesterday isn’t the same as what they’re wearing today. So how do we deal with this?
 We could look at what our scientists wore yesterday and then take the average of the two outfits. After all, in our data, scientists who wore purple tended to be ‘the best.’
We could look at what our scientists wore yesterday and then take the average of the two outfits. After all, in our data, scientists who wore purple tended to be ‘the best.’
But what about the day before? And last week? Last month? Last year? And how should we weigh outfits worn more recently versus those worn long ago?
The problem is that our knowledge of the scientists’ outfits is incomplete: we just don’t have a complete compendium of every single outfit that each scientist has worn.
And, even more worryingly, we don’t know all the other things that we’re not measuring. Some may correlate better with ‘bestness’, or there may be biases in the color measurement, but we’re blind to these features.
2. Low predictive power
Our funding scheme is also premised on a few important ideas.
(A) Previously, ‘bestness’ correlated with color;
(B) ‘Bestness’ in the past will predict ‘bestness’ in the future;
(C) In the future, ‘bestness’ will still correlate with color.
It turns out that both (B) and (C) are going to be problematic.
See, essentially, we’re evaluating the scientists on the science they did previously (with dress color as a proxy) and using that as an indication of the science they’ll do tomorrow. Yeah, there may be a relationship. But there also may not be. After all, just because a coin landed heads up is no indication that it will do so in the next toss.[4]
Moreover, the way we’re going to decide on funding in the future is by using dress color—but this relationship might break down.
Is this fear reasonable? Yes.
A great example of the fragility of correlative relationships is that of Google Flu Trends. For several winters, there was a nice correlation between search terms like “flu symptoms” and the spread of the virus. But then, in 2012, the relationship fell apart—and Google overestimated flu-like illnesses. So what’s to say that dress color will continue to be a good way to measure ‘bestness’?
3. Mimicry
Aside from, say, random chance, there’s an another reason why the correlation between color and ‘bestness’ might disappear—a reason so important that, even though technically it’s a subclass of reason 2, I’m considering it separately: mimicry.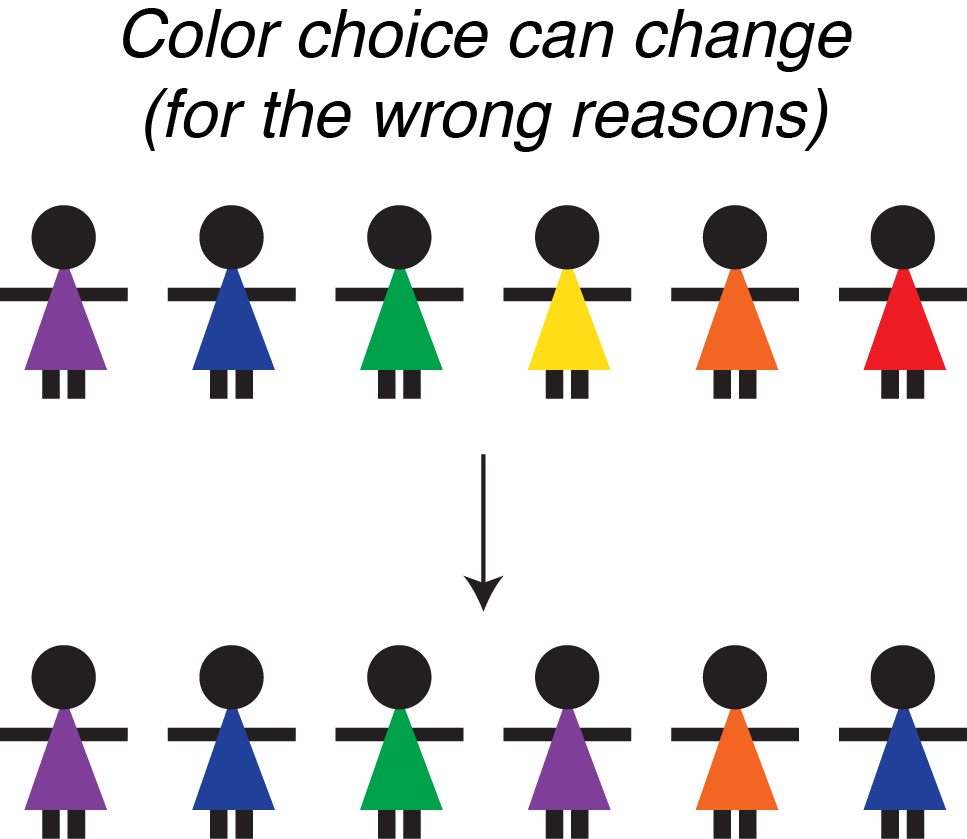
After our first round of funding, word gets out that we’re ranking scientists by color. And so, naturally, since scientists want to be funded, they start dressing in more purple and blue.
Now it may be that wearing purple causes scientists to be better. In this scenario, we probably want people to wear more purple!
But such a scenario tends to be the exception rather than the rule, and, most of the time, all we’ve got is a correlation between dress color and ‘bestness.’
So when scientists start dressing more in purple and blue without changing anything scientifically, the situation becomes very analogous to mimicry in nature, with bad and good scientists dressing more and more alike.[5]
Or to phrase this pitfall in another way: Scientists will game the system.
Even when we have all our ducks in a row, this problem is far from straightforward. Rarely can we measure ‘bestness’ itself, and so, most of the time, we’re just looking at traits that correlate bestness.
But our knowledge is incomplete.
It has limited predictive power.
Every scientist is trying to game the system—to dress in as much purple as possible. Sometimes, when we have causal relationships, that will make them be better scientists. But other times,—most of the time,—that will just make them look like better scientists.
So what should we do?
Clearly one option is to throw our hands up in the air and forgo measuring traits entirely. Presumably we might go by some je ne sais quoi—and go by what our intuition strikes as ‘best’. To be honest, though, I actually find this solution to be one of the most distasteful, being both utterly non-scientific and very likely to entrench biases.[6]
The approach I favor is one where we use multiple metrics. But we do so cautiously and skeptically. We never fool ourselves into thinking that our metrics are absolute and unchanging. We never pretend that our measurements are perfect and all-encompassing. We never stop analyzing our approach critically.
In short, I favor an approach where we never cease to be scientists, just because we start handing out money.
[1] See what I did there?
[2] Yes, all those preschool ROYGBV classes are finally paying off.
[3] Just to be explicit here: in the real world, “dress color” might mean “number of publications.” Or, in the case of college admissions, “grades.”
[4] To me, the lack of thoughtfulness on this point is one of the major flaws with funding decisions, promotions, school admittance, etc. And far too often, funding agencies point to the success of their scientists as proof that their selection criteria work (i.e. are predictive), but rarely do the agencies control for the idea that the very act of funding scientists causes them to be more successful.
[5] For instance, the ash borer has evolved to resemble the common wasp and is thus similarly avoided by predators because the wasp stings although the ash borer does not.
[6] e.g. gender and racial biases. I know I’m not the first one to point this out, but this idea was driven home to me (again) at a recent conference. Ten poster prizes were awarded—using such an intuitive ranking system,—but only two were given to women, despite a near-equal representation of women at the poster session itself.

You cannot fund the best scientists because there is no such thing as ‘best science’.What needs to be asked is if the science funded through the taxpayer is useful to the taxpayer or simply mental masturbation for the brilliant scientist who take these funds.
Major Breakthroughs come either from left field or are serendipitous; substantial progress comes from market driven funding.
None of these are indicators as they can apply to fancy but useless work(useless in terms of direct benefits to the public that provides the funds): Productivity,Efficiency ,Scientific significance,,Commitment to teaching(?);Creativity,Experience;Reputation. All except for Risk taking,which cannot be judged by a Government funding agency.